
Global Self-Attention for Transformers : Mathematical Explanation! How is it Different from Spatio-Temporal Attention?
Written By Chinmay Kapoor
Date Posted February 22, 2024

source: GPT-4
What is Global Self-Attention Mechanism? How is it used in Transformers.
The Global Self-Attention Mechanism is a core component of Transformer-based models, which are widely used in natural language processing (NLP) and other areas of machine learning. Introduced in the seminal paper “Attention Is All You Need” by Vaswani et al. in 2017, this mechanism fundamentally changed how sequences (e.g., sentences in text) are processed by neural networks.
Conceptual Overview
Self-Attention: At its heart, self-attention is a mechanism that allows each element in a sequence to consider (i.e., attend to) all other elements in the same sequence when computing its representation. For example, in a sentence, each word looks at all other words to better understand its context and meaning within that sentence.
Global Perspective: The term “global” indicates that the attention mechanism doesn’t focus on a small, localized part of the sequence but instead considers the entire sequence globally. This means each output element is influenced by all input elements, allowing the model to capture long-range dependencies and complex relationships between elements, which is particularly beneficial for tasks like translation, where context is crucial.
Technical Details
The mechanism computes three vectors for each element in the input sequence: a query vector, a key vector, and a value vector, using trainable linear transformations. The attention scores are then computed by taking a dot product of the query vector of one element with the key vector of every other element, followed by a softmax operation to normalize the scores. These scores determine the weighting of the value vectors, and the weighted sum of these value vectors becomes the output for each position.
Mathematical Representation
Given an input sequence, the self-attention output for each element is calculated as:
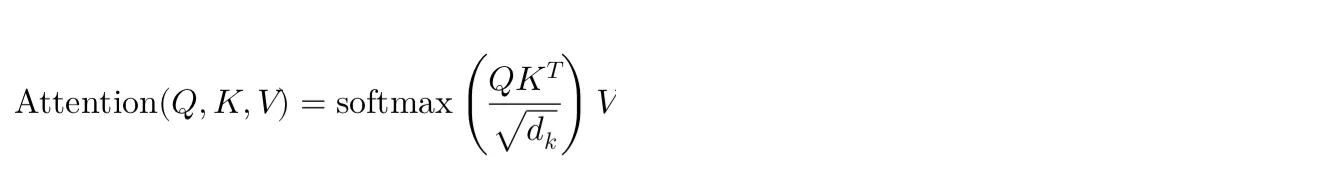
• Q,K,V are the matrices of queries, keys, and values, respectively.
• dk is the dimension of the key vectors, used for scaling to avoid overly large dot products.
Benefits and Applications
• Efficiency and Parallelization: Unlike RNNs and LSTMs, which process sequences step-by-step, self-attention mechanisms can process all elements of the sequence in parallel, leading to significant computational efficiency.
• Long-range Dependencies: It can capture relationships between elements far apart in the sequence, overcoming the limitations of models that process data in fixed-size windows.
• Flexibility: The mechanism is highly versatile and has been successfully applied beyond NLP to fields like computer vision and generative models.
The Global Self-Attention Mechanism is a key ingredient in Transformer models, underpinning the success of models like BERT, GPT (Generative Pre-trained Transformer), and others in achieving state-of-the-art results across a wide range of tasks.
Lets talk more about the mathematical representation:
Query, Key, and Value Vectors
For each element in the input sequence (e.g., a word in a sentence), the self-attention mechanism generates three vectors:
• Query Vector (Q): Represents the element that is seeking to gather information from other elements. It’s like asking, “What information is relevant to me?”
• Key Vector (K): Represents the elements that are being queried. It’s akin to saying, “Here’s how I can be identified for relevance.”
• Value Vector (V): Contains the actual information that needs to be passed along if the element is deemed relevant.
These vectors are obtained by multiplying the input embedding vector (representative of the sequence element) by three different weight matrices W^Q , W^K & W^V which are learned during training. For an input element x , the transformations are:
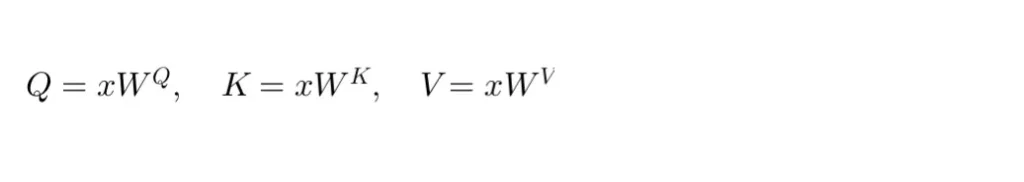
The essence of these transformations is to project the input into spaces that are conducive to querying (for relevance), being identified (for providing relevant information), and carrying the information to be shared, respectively.
Attention Scores and Softmax Function
Once we have the query, key, and value vectors, the next step is to compute the attention scores, which determine how much focus should be placed on other parts of the input sequence for each element. The attention score between a query and a key is calculated by taking the dot product of the query vector with the key vector of every other element, and then scaling it down by the square root of the dimension of the key vectors ((dk)^(1/2)) to prevent the dot product from growing too large in magnitude, which could lead to gradient vanishing problems during training.
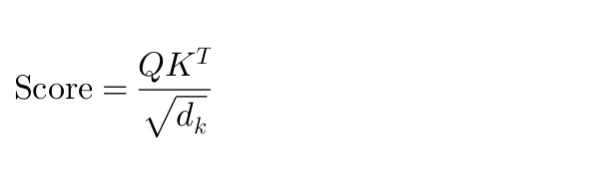
The softmax function is applied to these scores for each query, transforming them into a probability distribution:
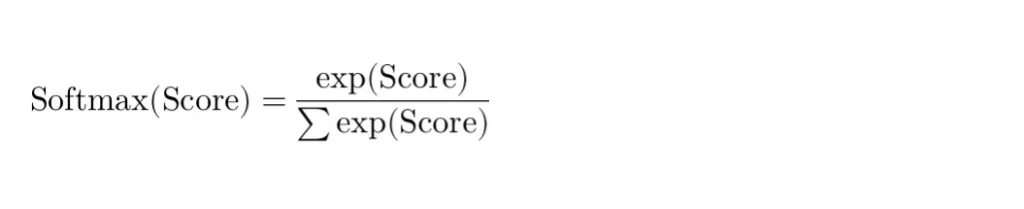
This step ensures that the scores are normalized to lie between 0 and 1, allowing them to be interpreted as probabilities. The softmax function is particularly suited for this task because it accentuates the largest values and suppresses the smaller ones, making the mechanism focus more on the elements that are most relevant according to the attention scores. This selective focus is crucial for effectively capturing dependencies and relationships within the sequence.
Why Softmax?
The softmax function is chosen over other normalization functions due to its ability to create a “winner-takes-all” scenario, where the highest scores get significantly more weight, and the lower scores are nearly zeroed out. This is desirable in the context of attention mechanisms because it allows the model to focus on the most relevant information while ignoring the less relevant. Alternative functions like sigmoid could also transform scores into a 0 to 1 range but would treat each score independently, failing to provide the competitive aspect that softmax introduces by considering all scores together when normalizing.
The query, key, and value vectors facilitate a flexible and powerful mechanism for modeling relationships within data. By using the softmax function to normalize attention scores, the Global Self-Attention Mechanism ensures that the most relevant information is amplified and less relevant information is diminished, allowing neural networks to focus on what is most important within a given context. This mathematical foundation underpins the remarkable success of Transformer models across a wide array of tasks.
FURTHER EXPLANATION Using EXAMPLE:
To clarify the concepts of query, key, and value vectors in the context of self-attention mechanisms, let’s use a simplified example. Imagine we’re analyzing a sentence to understand the context and relationships between words using self-attention. The sentence is:
“The cat sat on the mat.”
In a self-attention mechanism, each word in this sentence will be transformed into query (Q), key (K), and value (V) vectors through learned weight matrices. Let’s break down what these vectors represent and how they interact with one another for a single word to illustrate the process.
Step 1: Vector Representation
First, each word is represented by an embedding vector (a dense vector of fixed size). For simplicity, assume we’re focusing on the word “cat”.
• Original Vector for “cat”: [0.2, -0.1, 0.9] (simplified representation)
Step 2: Transformation into Q, K, and V
This vector is then transformed into three different vectors by multiplying it with three different weight matrices (for query, key, and value). These transformations are part of the model’s learned parameters.
• Query Vector (Q) for “cat”: It’s used to determine how much attention “cat” should pay to other words. Let’s say, [0.5, -0.3, 0.8].
• Key Vector (K) for “cat”: It’s used by other words to decide how much attention they should pay to “cat”. Assume it’s [0.1, 0.2, -0.1].
• Value Vector (V) for “cat”: Contains the information that “cat” contributes to the sentence representation, say [1.0, 0.1, 0.5].
Step 3: Calculating Attention Scores
Attention scores between “cat” and another word in the sentence, say “mat”, are calculated using the dot product of “cat”’s query vector with “mat”’s key vector. This score determines how relevant “mat” is to understanding the context of “cat”.
• Example: If “mat”’s key vector is [0.3, 0.4, -0.2] and “cat”‘s query vector is [0.5, -0.3, 0.8], the attention score would be the dot product of these two vectors. For simplicity, let’s say this results in a score of 0.24.
Step 4: Softmax Normalization
The attention scores from “cat” to all words in the sentence, including itself, are normalized using the softmax function to convert them into probabilities. This process ensures that the scores sum up to 1, making it easier to interpret them as the likelihood of each word’s relevance to “cat”.
Step 5: Weighted Sum of Value Vectors
Finally, the normalized attention scores are used to create a weighted sum of all the value vectors in the sentence. This sum represents the new context-aware representation of “cat”.
• Example: If “mat” has a high normalized attention score with “cat”, its value vector will contribute more to the final representation of “cat”.
Simplified Summary
In this process:
• Query vectors are like questions a word asks about every other word, including itself.
• Key vectors are like identities that each word presents in response to the questions.
• Value vectors are the actual content or information that each word offers, weighted by how relevant it is to each question (i.e., the context).
Through this mechanism, the model dynamically focuses on different parts of the sentence, depending on what each word is “asking” and “answering”, thus encoding the sentence with rich, context-aware representations.
Conclusive Summary
The Global Self-Attention Mechanism, introduced in the transformative work “Attention Is All You Need” by Vaswani et al. (2017), has revolutionized the field of artificial intelligence, especially within natural language processing (NLP) and computer vision. This mechanism enables models to process sequences, such as text, in a way that each element in the sequence considers all other elements, thereby capturing the global context and intricate relationships within the data. Key components of this mechanism include the query (Q), key (K), and value (V) vectors, which are generated for each element in the input sequence through trainable linear transformations. The interaction between these vectors, through the computation of attention scores followed by softmax normalization, allows the model to dynamically focus on the most relevant parts of the input data. This process results in a weighted sum of value vectors that forms the output for each position, enabling the model to understand long-range dependencies and complex relationships effectively. The Global Self-Attention Mechanism stands out for its efficiency, allowing parallel processing of sequence elements, unlike the sequential processing of RNNs and LSTMs. Its flexibility and the ability to capture long-range dependencies have made it a cornerstone of modern Transformer-based models like BERT and GPT, driving significant advancements across a wide range of AI tasks.
Comparatively, Spatio-Temporal Attention extends the principles of self-attention to both spatial and temporal dimensions, making it particularly suited for applications that require an understanding of how spatial relationships evolve over time, such as in video processing.
In summary, the Global Self-Attention Mechanism has set a new standard in machine learning by enabling more nuanced and context-aware processing of sequential data. Its development marks a significant milestone in the journey towards creating more intelligent and capable AI systems.